maps I've made over the years
ENPLAN Wildfire Viewer
Enhanced and improved wildfire maps (2008)
In 2008 I was evacuated from my house by several wildfires started by a massive lightning storm. I was frustrated that the existing map information from State and Federal organizations was poorly designed and presented. Their mapping platforms were also not designed to handle large amounts of traffic so more often than not the maps would be extremely slow or not work at all. I built a system to scrape the data and host it on Amazon AWS, and a lightweight modern front end website. This was the first online wildfire map to use a "slippy map" base. At its peak it served maps to 80,000 visitors a day.
Google Static Maps Playground
Experiment with Google Static Maps (2010)
I taught several classes on introductory web mapping on GIS Day. This page introduces the different parameters used to configure Google Static Maps.
Shasta County Crime Map
Online map of incidents as reported by the Shasta County Sheriff's Department (2010, now defunct)
Every night a department employee would print out the incident log from the dispatch system, redact the names of minors with a felt pen, and scan the pages to PDF. I built a system to download each day's report, OCR it with OCRopus, and parse out the incident time, location, and description. The data was then loaded into GeoCouch for display in OpenLayers.
Colorado Gravel Roads
Every gravel road in Colorado (2011)
After moving to Colorado I wanted a map of all the gravel roads so I could plan bicycle routes. I found that the state DOT had the data available for download, so I used TileMill to generate an MBTiles tileset and some custom Python code to extract the individual tiles and copy them to Amazon S3. The whole website runs statically in S3. A Cloudfront distribution serves the pages over HTTPS as required for geolocation.
Iowa Gravel Roads
Every gravel road in Iowa (2012)
Similar to coloradogravelroads.com. The unfortunate red/green symbology matches the state PDF maps. This later became a shirt, and then a print.
Nebraska Gravel Roads
Every gravel road in Nebraska (2014, work in progress)
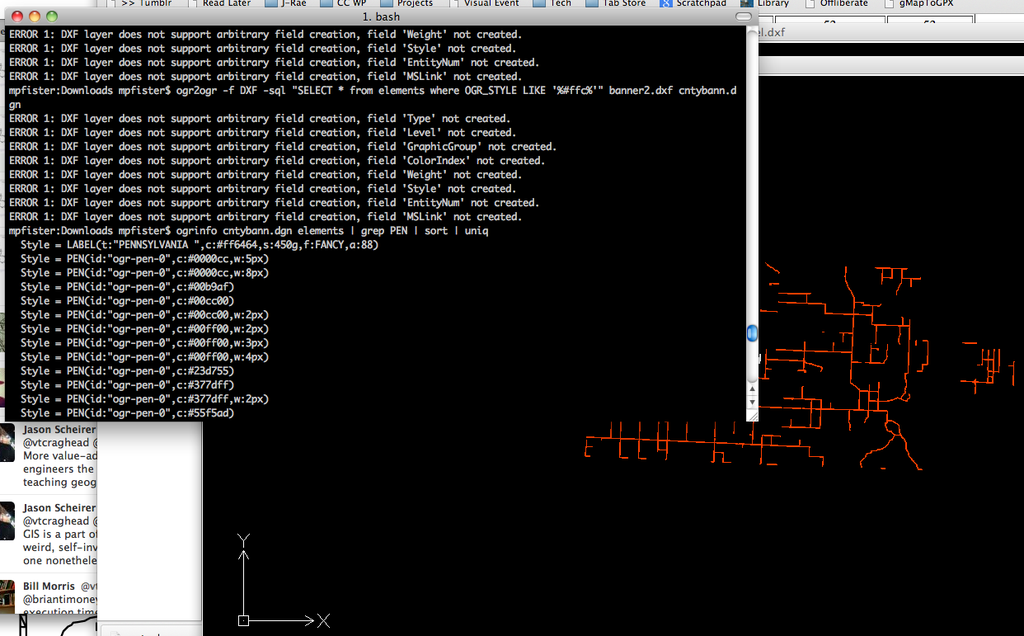
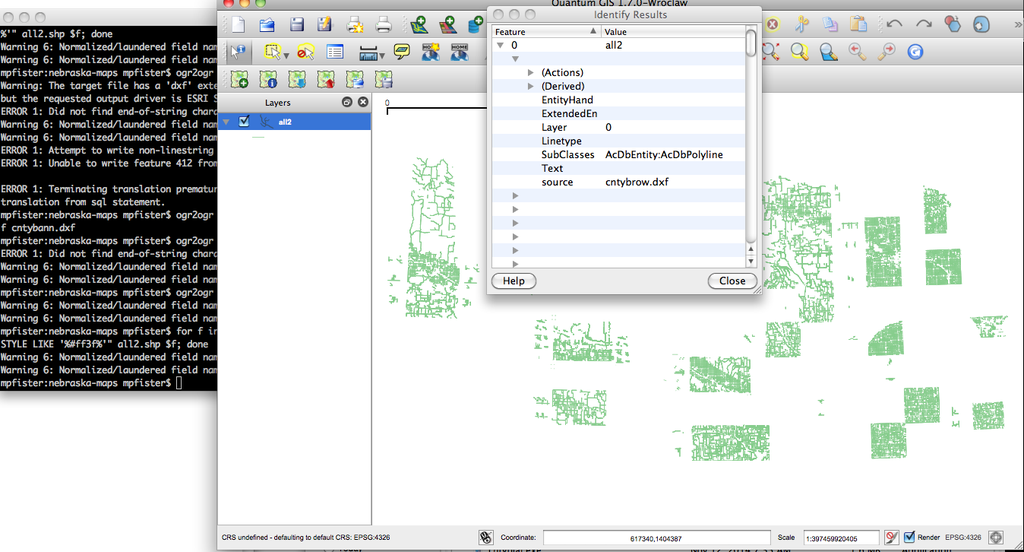
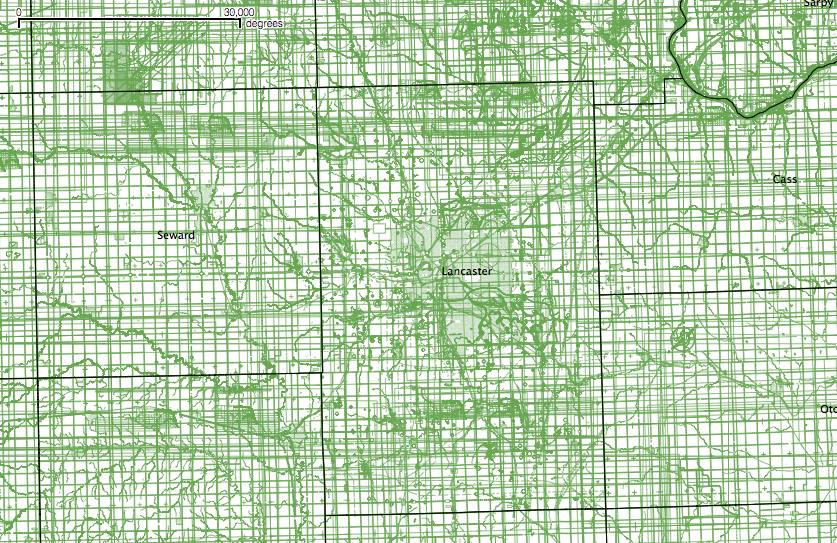
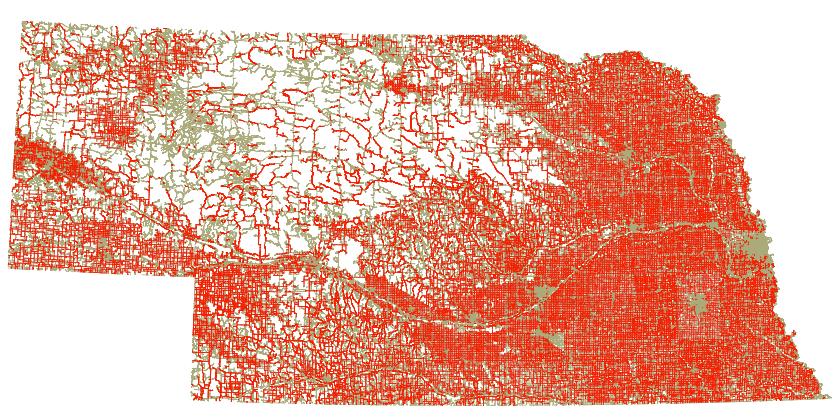
The site I wanted to build when I lived in Nebraska prior to moving to Colorado. Nebraska has county road maps showing the road surface type. Unfortunately, the data is only available as a mix of Microstation v7 and v8 DGN files, and they're drawn specifically to be paper prints. After converting them to DXF I was able to extract the dirt roads using OGR SQL syntax targeting the plotter pen style information, and with some additional geometry hacking with PostGIS and TIGER data I was able to do a pretty good job extracting the unpaved roads across the state. It needs some verification, so at some point I plan to experiment with machine learning to see if the surface type can be automatically checked against aerial imagery.
(preparation) (progress) (before) (after)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Greeley Oil Wells
A complete rework of a complicated and ugly process (2016)
Originally when someone requested information about oil wells and drilling within the City of Greeley, a GIS technician would go to the Colorado Oil and Gas Commission website to find and download the latest shapefiles. They would then update an ArcView map with the new data, and export a PDF of the map and an Excel spreadsheet. The map was a full page in color, using a busy basemap, confusing symbology, and default line weights. An employee in the planning department would then take the spreadsheet, reformat it and make some calculations, and print it to PDF. The goals of this project were to automate the entire process and simplify the map and table into a single black and white page. Now every night the data is automatically downloaded and a new document is generated. The cartography was simplified and all line weights and symbology were picked specifically for this presentation. The table data was condensed into simpler classifications. Overall the page tries to maximize the data to ink ratio.
Dakota Gravel Roads
Every gravel road in the Dakotas (2017)
After riding the Mickelson trail in South Dakota I looked for data for that state to make another gravel roads map and found that both of the Dakotas had surface type data. This map modernizes my previous maps by switching from Leaflet with image tiles to MapboxGL with vector tiles. The tiles were generated with Tippecanoe and are stored as gzipped PBFs. This map is also hosted completely on Amazon S3 and Cloudfront.
Greeley Business Data
A prototype for examining business data (2017)
A standard D3 infoviz style of map, using Leaflet's markercluster and heatmap plugins for the two views and Crossfilter for the data store. More notable is the back end, a Jupyter notebook that takes three data sources - internal tax database records, State employment data, and a GIS feature class, and normalizes the records across all three. It then outputs optimized JSON datasets for the business locations and the NAICS codes that can be served statically.